
Log4KJS
Spring Kafka 의 Async ack 활용 본문
Apache Kafka 는 가장 많이 쓰이는 로그 기반 메세지 브로커입니다.
카프카의 특징 중 하나로는 메세지를 추가 전용 로그(파티션) 에 연속적으로 기록한다는 점입니다. 즉, 프로듀서가 보낸 메세지는 로그 끝에 추가되고, 컨슈머는 일정 주기로 로그에서 메세지를 poll 해옵니다. 이러한 구조 때문에, Kafka 는 각 메세지마다 ack 를 관리하고 ack 된 메세지를 삭제하는 방식이 아닌, 각 파티션마다 컨슈머 그룹 별로 오프셋을 관리하고, 컨슈머는 메세지를 순차적으로 처리한 후 오프셋을 커밋하는 방식을 이용합니다.

(단일 컨슈머가 여러개의 파티션을 소비하는 것은 허용되지만, 한 파티션은 반드시 컨슈머 그룹별로 한개의 컨슈머에만 연결되어야 합니다)
그림에서는 2,3,4 를 poll 한뒤 메세지를 처리하고 offset 을 한번에 커밋했지만, 스프링 카프카에서는 AckMode 를 이용해 이를 설정할 수 있습니다.
• RECORD: listener 가 반환된 뒤, 개별 레코드별로 커밋
• BATCH: poll() 로 가져온 레코드들이 모두 처리된 후 커밋 (위 그림의 경우)
• MANUAL: Message Listener 에 전달된 Acknowledgement 의 acknowledge() 또는 nack() 을 직접 호출해야
합니다. 실제 커밋은 poll() 로 가져온 레코드들이 모두 처리된 후 이루어집니다. nack() 호출시 커밋 대기중인 오프
셋(이미 ack 된)까지는 바로 커밋되고 nack 된 메세지는 다음 poll() 에 다시 가져오게 됩니다.
이는 DefulatErrorHandler 의 동작과 같습니다.
• MANUAL_IMMEDIATE: acknowledge() 호출시 poll() 로 가져온 메세지들을 다 처리할때까지 기다리지 않고
즉시 커밋합니다.
(트랜잭션이 활성화되었다면 AckMode 에 상관 없이 message listener 가 반환된 뒤 커밋 또는 롤백을 실행합니다.)
이렇듯 카프카는 메세지별로 상태를 관리하는 것이 아니라 파티션별 오프셋을 관리하기 때문에, 기본적으로 한 파티션의 메세지를 순차적으로 처리해야 합니다. 하지만 이는 개별 메세지의 처리 비용이 클때 문제가 되었는데요, 구체적으로 다음과 같은 상황이었습니다.
Community 에는 게시글 업로드 이벤트를 받아 팔로워의 피드에 푸쉬해주는 역할을 수행하는 Dispatcher 서버가 존재합니다. Dispatcher 가 카프카로부터 하나의 메세지를 받아 처리하는 과정은 다음과 같습니다.
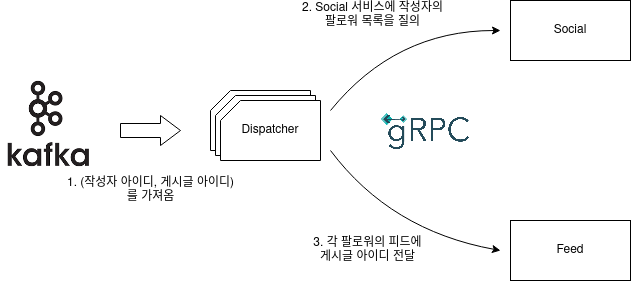
하나의 메세지 처리에 네트워크 통신이 두번 끼어있기 때문에 비용이 상당히 높은 상황입니다. 이런 상황에서 메세지를 순차적으로 처리한다면, IO 대기 시간이 길어 만족할만한 처리량을 보장하지 못할 것이라고 생각하였습니다. 따라서 다음과 같은 방법을 사용하여 해결하였습니다.
소켓 IO 로 인해 blocking 되는 시간을 줄이려면, non-blocking 한 비동기 호출을 사용하면 됩니다. gRPC 의 Async Stub 와 Reactor 프레임워크를 사용하여 다음과 같이 코드를 구성하였습니다.
@Slf4j
@RequiredArgsConstructor
public class PushService {
private final PagedFollowerFetcher fetcher;
private final FeedPusher pusher;
public Mono<Void> dispatchPostIdToFollowers(PagedAuthorInfo authorAndPost) {
long authorId = authorAndPost.getAuthorInfo().getAuthorId();
long postId = authorAndPost.getAuthorInfo().getPostId();
Flux<Long> followerIds = fetcher.getFollowers(authorId, authorAndPost.getRequest());
return followerIds.flatMap(followerId -> tryPush(new FeedElement(followerId, postId))).then();
}
private Mono<Void> tryPush(FeedElement element) {
return pusher.pushFeed(element)
.doOnError(e-> log.error("피드 푸쉬 실패; follower id: {}, post id: {}", element.getFeedOwnerId(), element.getPostId()));
}
}
gRPC 가 내부적으로 Netty Channel 을 이용하기 때문에 이와 같은 방법을 통해 적은 스레드로 높은 동시성을 확보할 수 있었습니다. 하지만, 아직 한가지 문제가 남아있었는데요, kafka message listener 단에서 어떻게 ack 를 수행해야 하는지에 대한 문제였습니다.
기본적으로 ack 는 메세지 브로커가 메세지의 처리를 보장하기 위해 존재합니다. 다음과 같은 세가지 시맨틱이 있습니다.
1. At least once
메세지가 적어도 반드시 한번은 처리되어야 합니다. 메세지가 여러번 처리될 수 있습니다.
트랜잭션 없이 카프카가 제공하는 기본적인 시맨틱입니다. 컨슈머가 메세지를 처리한 후 브로커에게 ack 를 전달합니다.
2. At most once
메세지가 최대 한번 처리되어야 합니다. 컨슈머 장애시 메세지가 처리되지 않을 수 있습니다.
auto commit 을 활성화하여 카프카가 메세지를 보낸 직후 ack 를 기다리지 않고 offset 을 commit 하게 하면 됩니다.
3. exactly once
메세지가 정확히 한번 처리되어야 합니다. 트랜잭션의 도움이 필요합니다.
kafka 에 offset 을 커밋하는 오퍼레이션과, 메세지를 처리 후 결과를 출력하는 오퍼레이션 ( 다른 카프카 토픽에 발행, rdb 에 저장) 등을 하나의 트랜잭션으로 묶어야 합니다. 카프카는 XA transaction 을 지원하지 않기 때문에 Kafka Connect 를 사용하거나,
단순히 두 트랜잭션을 체이닝하는 방법을 생각해 볼 수 있습니다.
위 유스케이스에서 필요한 시맨틱은 At least once 였습니다. 팔로워의 피드에 게시글 아이디가 적어도 한번은 전달되어야 하지만,
여러번 전달되어도 문제가 되지는 않기 때문입니다. 정리하자면, 메세지를 병렬적으로 처리하면서, at least once 시맨틱을 보장해야 합니다.
이를 위해 KafkaMessageListenerContainer 가 제공하는 Async Ack = true 설정을 사용하였습니다.
Async Ack 는 AckMode.MANUAL 과 AckMode.MANUAL_IMMEDIATE 와 함께 사용될 수 있는 옵션으로,
ack를 consumer thread 가 아닌 다른 스레드에서 수행할 수 있게 해줍니다. 정확히는, consumer thread 로 하여금 메세지가 acknowledge() 되어도, 그 이전 메세지가 아직 acknowledge() 되지 않았다면 ack 를 지연합니다.
KafkaMessageListenerContainer 의 코드를 살펴보겠습니다.
private synchronized void ackInOrder(ConsumerRecord<K, V> record) {
TopicPartition part = new TopicPartition(record.topic(), record.partition());
List<Long> offs = this.offsetsInThisBatch.get(part);
List<ConsumerRecord<K, V>> deferred = this.deferredOffsets.get(part);
if (offs.size() > 0) {
if (offs.get(0) == record.offset()) {
offs.remove(0);
ConsumerRecord<K, V> recordToAck = record;
if (deferred.size() > 0) {
Collections.sort(deferred, (a, b) -> Long.compare(a.offset(), b.offset()));
while (deferred.size() > 0 && deferred.get(0).offset() == recordToAck.offset() + 1) {
recordToAck = deferred.remove(0);
offs.remove(0);
}
}
processAck(recordToAck);
if (offs.size() == 0) {
this.deferredOffsets.remove(part);
this.offsetsInThisBatch.remove(part);
}
}
else if (record.offset() < offs.get(0)) {
throw new IllegalStateException("First remaining offset for this batch is " + offs.get(0)
+ "; you are acknowledging a stale record: " + ListenerUtils.recordToString(record));
}
else {
deferred.add(record);
}
}
else {
throw new IllegalStateException("Unexpected ack for " + ListenerUtils.recordToString(record)
+ "; offsets list is empty");
}
}
Acknowledgement.acknowledge() 를 호출하면 수행되는 코드입니다. offsetsInThisBatch 는 아직 처리되지 않은 메세지들을 담고 있고, deffered 는 ack 가 지연된 레코드들을 저장합니다.
먼저, acknowledge() 한 레코드가 offsetsInThisBatch 중 가장 작은 오프셋을 가진 레코드인지 확인합니다. 가장 작은 오프셋을 가진 레코드인 경우, deffered 를 읽으면서 어디까지 ack 할 수 있는지 확인하고, processAck 를 호출합니다. processAck 는 this.acks 에 레코드를 저장하여 ack 되어야 할 레코드임을 알리고 후술할 pause 된 컨슈머를 깨웁니다. 가장 작은 오프셋을 가진 레코드를 acknowledge() 한 것이 아닌 경우에는 해당 레코드를 deffered 에 추가하여 ack 를 지연합니다.
컨슈머 스레드는 this.acks 를 확인해 커밋해야하는 경우 커밋을 수행하고, poll() 로 가져온 레코드들이 모두 처리되지 않았다면 pause 상태로 들어갑니다.
@RequiredArgsConstructor
@Slf4j
public class KafkaPushApi implements AcknowledgingMessageListener<Long, PagedAuthorInfo> {
private final PushService pushService;
@Override
public void onMessage(ConsumerRecord<Long, PagedAuthorInfo> data, Acknowledgment ack) {
pushService.dispatchPostIdToFollowers(data.value()).subscribe(null,
onError(ack, data.value()),
onComplete(ack, data.value()));
}
private Consumer<? super Throwable> onError(Acknowledgment ack, PagedAuthorInfo data) {
return ex -> {
ack.acknowledge();
log.error("피드 푸쉬 실패; 작성자 아이디: {}, 게시글 아이디: {}, 페이지: {} / {} ",
data.authorId(), data.postId(), data.pageIndex(), data.totalPage());
};
}
private Runnable onComplete(Acknowledgment ack, PagedAuthorInfo data) {
return ()-> {
ack.acknowledge();
log.debug("피드 푸쉬 성공; 작성자 아이디: {}, 게시글 아이디: {}, 페이지: {} / {} ",
data.authorId(), data.postId(), data.pageIndex(), data.totalPage());
};
}
}
Async Ack 를 사용하면 위와 같이 Message Listener 에서 ack 순서를 상관하지 않고 코드를 구성할 수 있습니다.
단, nack 은 Consumer Thread 가 아닌 스레드에서 호출할 수 없으므로 onError 에서 실패한 레코드를 토픽에 재발행하는 등의 recovery 를 추가해 주는 것이 좋습니다.
'Project' 카테고리의 다른 글
| Community - Push 기반 소셜 네트워크 서비스 (1) | 2022.02.19 |
|---|---|
| Redis pipelining (feat. Spring + Lettuce) (0) | 2022.02.19 |
| Grpc NameResolver + Eureka Service Discovery (0) | 2022.02.17 |
| Cachy 의 스레딩 모델과 성능 개선 (0) | 2022.02.05 |
| Cachy - 로그 구조화 key-value 저장소 (1) | 2021.12.18 |



