
Log4KJS
Cachy - 로그 구조화 key-value 저장소 본문
Cachy 는 <데이터 중심 애플리케이션 설계> 를 읽고,
<03. 저장소와 검색> 챕터의 내용을 기반으로 구현한 로그 구조화 저장소입니다.
여기서 말하는 로그란 추가 전용 파일 (AOF - Append Only File) 을 의미하는데요,
이해를 돕기 위해 아주 간단한 로그 기반 저장소를 생각해 보겠습니다.

이 로그 기반 저장소에서 쓰기는 단순히 추가 전용 로그(파일)의 끝에 key-value 쌍을 기록합니다. 이전에 같은 키에 대한 기록이 있더라도 덮어쓰기 않고, 단순히 파일의 끝에 키-값을 기록합니다. 이런 sequential write 는 random write 보다 빠르기 때문에 쓰기 작업은 매우 효율적으로 이루어질 수 있습니다.
하지만 문제는 읽기에서 발생합니다. 파일에 기록된 키-값 쌍들에는 어떠한 순서도 없고, 키를 여러번 갱신해도 예전 값을 덮어쓰지 않기 때문에 최신 값을 찾기 위해서는 파일을 처음부터 끝까지 읽어야합니다. 이는 O(N) 의 시간복잡도로, 데이터가 두배 늘어나면 검색도 두 배 오래 걸리게 됩니다.
특정 키의 값을 효율적으로 찾기 위해서는 다른 데이터 구조가 필요합니다. 이를 색인(index) 이라고 부릅니다.
색인은 데이터베이스의 내용에는 영향을 미치지 않고, 질의 속도를 향상시킵니다. 하지만 많은 경우, 색인을 추가하게 되면 쓰기 과정에서 색인을 갱신해야 하므로 오버헤드가 발생하게 되고, 쓰기가 느려집니다. (쓰기 증폭)
이는 저장소 시스템에서 중요한 trade-off 중 하나라고 할 수 있습니다.
SS Table, LSM Tree
위에서 살펴본 로그 세그먼트 파일의 형식에 간단한 변경 한 가지를 적용해 봅시다. 바로 key-value 쌍을 키로 정렬하는 것입니다.
(언뜻 보기에 이 요구사항은 순차 쓰기를 허용할 수 없는 것처럼 보이지만, 이 부분에 관한 설명은 더 아래에서 기술하겠습니다)
이처럼 키로 정렬된 형식을 정렬된 문자열 테이블 (Sorted String Table) 또는 짧게 SS 테이블이라고 부릅니다.
SS 테이블에는 몇가지 장점이 있습니다.
1. 세그먼트끼리의 병합이 간단합니다.
로그 구조화 데이터베이스에서는 키를 여러번 갱신해도 예전 값을 덮어쓰지 않기 때문에 같은 키에 대한 값이 여러번 쓰일 수 있습니다. 이 때문에, 같은 파일에 계속 추가만 진행한다면 결국 디스크 공간이 빠르게 부족해질 것입니다. 따라서 특정 크기의 세그먼트(segment) 로 로그를 나누는 것이 좋은 해결책입니다. 세그먼트 파일이 특정 크기에 도달하면 파일을 닫고, 새로운 세그먼트 파일에 쓰기를 수행합니다. 그런 뒤, 세그먼트 파일들에 대해 컴팩션(compaction) 을 진행하여 중복된 키를 버리고 각 키의 최신 값만 유지시킬 수 있습니다.
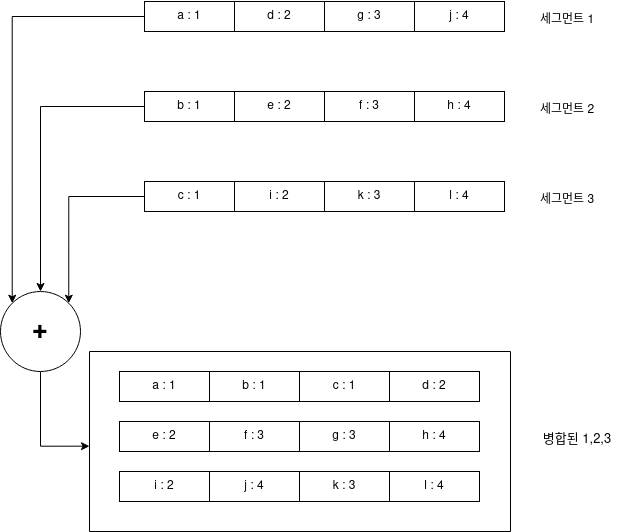
세그먼트 파일이 SS Table 일 경우, 병합정렬(merge sort) 를 이용하여 각 세그먼트의 크기가 가용한 메모리보다 크더라도 병합할 수 있습니다. 병합된 세그먼트 파일도 역시 SS Table, 즉 키로 정렬되어 있습니다.
병합 과정에서 같은 키를 발견할 경우, 더 최신 값을 기록하고 나머지 값들을 무시하는 방식으로 중복된 키값을 제거할 수 있습니다.
각각의 src 세그먼트에 대해 순차 읽기, dest 세그먼트에 대해 순차 쓰기를 사용하기 때문에 효율적입니다.
2. 메모리에 모든 키의 색인을 유지할 필요가 없습니다.

SS Table 이 디스크에 키를 기준으로 정렬되어 있으므로 메모리에 블럭단위로 key - file offset 을 저장하여 색인으로 사용할 수 있습니다. 몇 kb 단위의 읽기는 아주 빠르게 수행될 수 있으므로 최소 색인을 이용해 키값이 포함된 블럭을 찾고 해당 오프셋부터 블럭 전체를 읽어 key-value 쌍을 찾을 수 있습니다.
Cachy 의 구현
이처럼 SS Table 은 매우 유용하지만, 유입되는 쓰기를 어떻게 키로 정렬하여 디스크에 기록할지에 대한 문제가 남아있습니다.
유입되는 쓰기는 임의 순서대로 발생하기 때문입니다. 디스크 상에 정렬된 구조를 유지하는 일은 가능하지만
(RDB 의 B tree 와 같이) random disk write 가 발생하게 되고, 메모리에 유지하는 편이 훨씬 쉽습니다. 레드 블랙 트리나 AVL 트리와 같이 잘 알려진 Balanced Tree 를 사용하면 유입된 임의 쓰기를 정렬된 순서로 읽을 수 있습니다.
로그 구조화 저장소의 구현은 이제 다음과 같습니다.
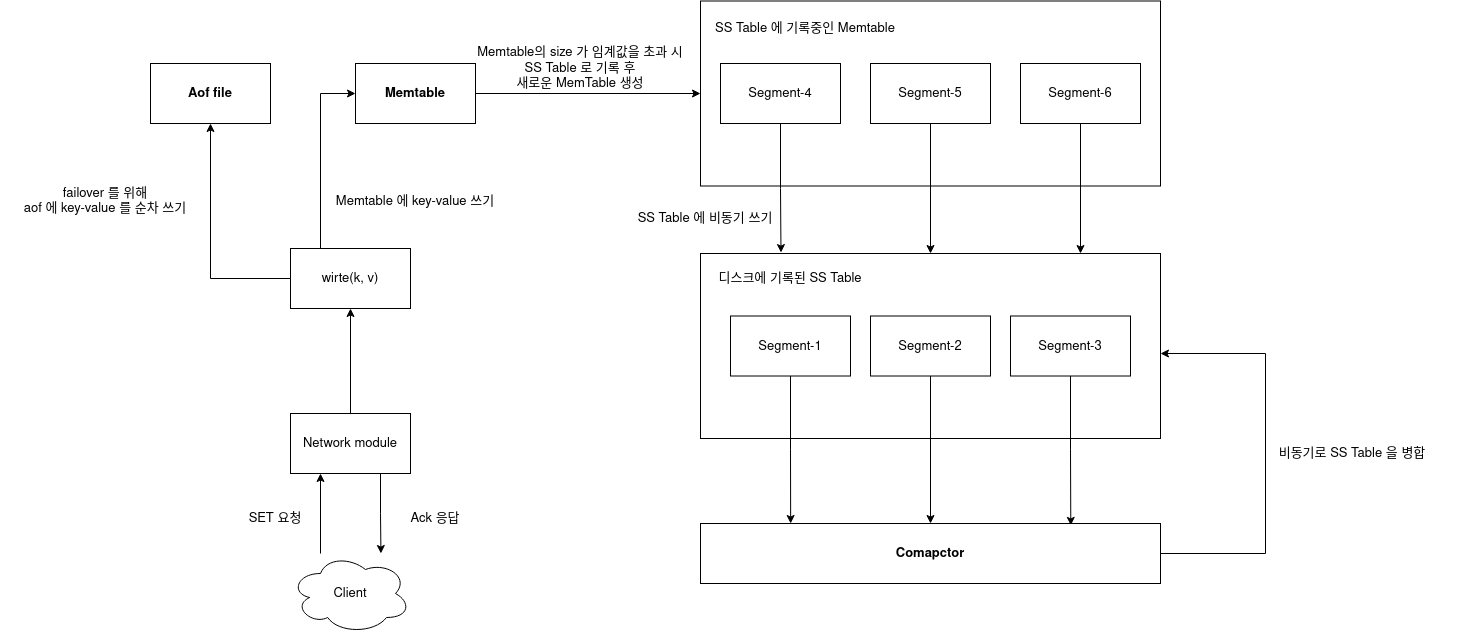
- 쓰기가 들어오면 인메모리 균형 트리에 데이터를 추가합니다. 이 트리를 Memtable 이라고 합니다.
- Memtable 이 특정 임곗값보다 커지면 SS 테이블로 디스크에 기록합니다. Memtable 이 이미 정렬된 순서를 유지하고 있기 때문에 이 과정은 매우 효율적으로 이루어질 수 있습니다. 이는 비동기적으로 이루어지고, SS 테이블로 디스크에 기록하는 동안 쓰기는 새롭게 생성된 Memtable 에 이루어집니다.
- 읽기 요청을 제공하려면 먼저 멤테이블에서 데이터를 찾고, 그다음 디스크 상의 최신 세그먼트에서 찾습니다. 키가 없으면 두번째, 세번째... 순으로 값을 찾습니다.
- 비동기적으로 인접한 SS Table 을 병합합니다.
이 구현은 아주 잘 동작하지만 한 가지 문제가 있습니다. 만약 데이터베이스가 고장나면 디스크에 SS Table 로 기록되지 않고 멤테이블에 있는 최신 쓰기들은 손실됩니다. 이런 문제를 해결하기 위해 쓰기에 대한 응답(ack) 를 보내기 전에 분리된 추가 전용 로그(Aof) 를 기록해야 합니다. 이 로그는 Memtable 을 복원할 때만 필요하기 때문에 순서가 정렬되지 않아도 문제가 없습니다.
Memtable 을 SS Table 로 기록하면 해당 로그는 삭제할 수 있습니다.
GitHub: https://github.com/IceMelon404/CachyServer
'Project' 카테고리의 다른 글
| Community - Push 기반 소셜 네트워크 서비스 (1) | 2022.02.19 |
|---|---|
| Redis pipelining (feat. Spring + Lettuce) (0) | 2022.02.19 |
| Grpc NameResolver + Eureka Service Discovery (0) | 2022.02.17 |
| Spring Kafka 의 Async ack 활용 (0) | 2022.02.11 |
| Cachy 의 스레딩 모델과 성능 개선 (0) | 2022.02.05 |



